
前言
HashMap是一个基于哈希实现的无序散列表,存储内容是键值对(key-value),非线程安全。其定义如下:
|
|
可以看到HashMap继承AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
本文源码分析基于jdk 1.8.0_121
继承关系
HashMap继承关系
|
|
关系图
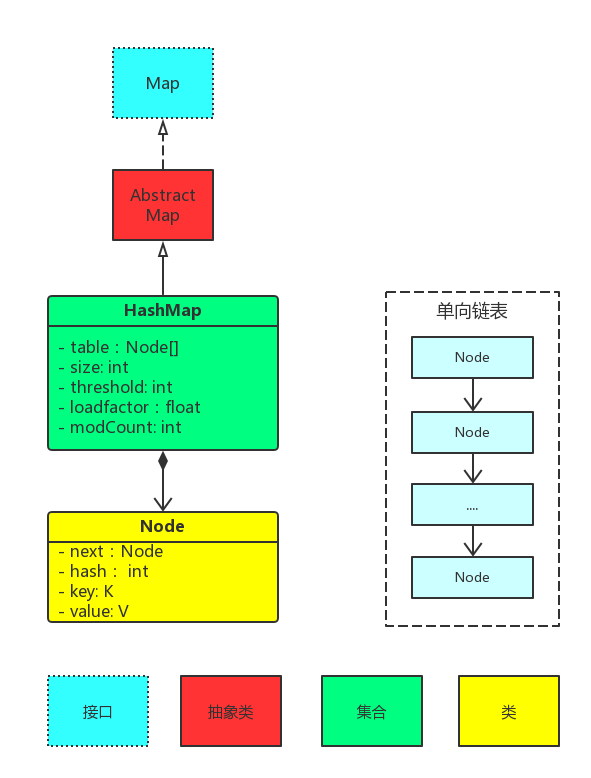
table是Node型的数组,而Node其实是个单向链表,所以HashMap的底层实现是由数组和链表实现的size是HashMap的实际大小threshold为是否需要调整HashMap的容量的阈值,等于加载因子乘以容量,当size达到threshold时,便对HashMap扩容至原来的两倍loadFactor是加载因子modCount是修改HashMap结构的计数值,用来实现fail-fast机制
需要注意的是在JDK 1.8以前HashMap的实现是数组+链表,但是哈希函数很难将元素百分百均匀分布,因此可能出现有大量的元素都存放到同一个桶中,那么便会出现一条长链表, HashMap 就相当于一个单链表结构,遍历的时间复杂度变成 O(n)。JDK 1.8时引入红黑树结构来优化此种现象,时间复杂度为O(logn)。当单个链表长度大于8时,就会将链表结构转为红黑树结构,示意图如下:
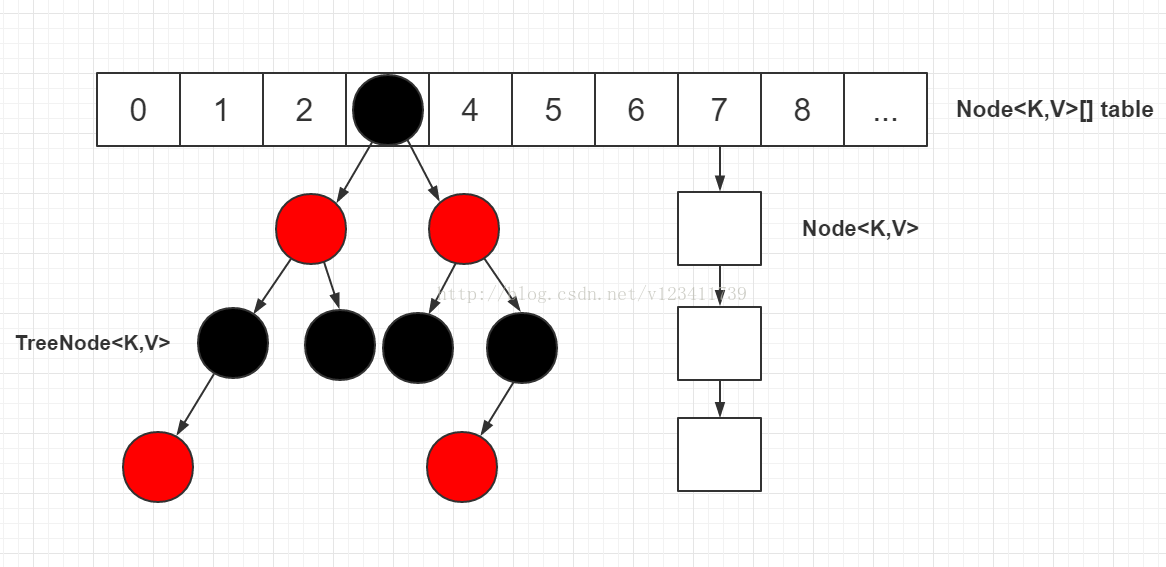
图片来源【文斯莫克香吉士】博客,博客地址见参考信息【Java集合:HashMap详解(JDK 1.8)】
数据结构
链表节点数据结构定义如下:
红黑树的节点数据结构定义如下:
可以看到TreeNode继承于LinkedHashMap.Entry,而 LinkedHashMap.Entry 继承自 HashMap.Node。
构造函数
|
|
从上述构造函数中我们可以看到影响HashMap的容量主要有初始容量大小initialCapacity和加载因子loadFactor,初始容量是指哈希表中桶的数量,当哈希表中的条目数与当前容量的比值超出了加载因子时,则要对该哈希表进行 rehash/resize 操作(即重建内部数据结构),将哈希表容量增加一倍。默认的加载因子是0.75,这是结合空间成本和时间成本给出的一个经验值,加载因子过大,增加时间成本;加载因子过小,则增加空间成本。因此,选取合适的加载因子很重要,可以减少rehash的次数。
API
|
|
源码分析
成员变量
|
|
构造函数
|
|
定位桶位置
|
|
对于给定的key,只要其hashCode()的返回值一样,那么其hash值就一样,如果用hash值对table长度取模,那么便可以让哈希表的元素分布相对均匀点。
此处源码对取模运算进行了优化,table的长度总是2的n次幂,而x mod 2^n = x & (2^n - 1),因此源码使用i = (n - 1) & hash来对table长度取模,从而找到对应的索引位置,&比%具有更高的效率。
增加元素
|
|
红黑树增加元素
|
|
获取元素
|
|
红黑树获取节点
|
|
删除元素
|
|
resize
|
|
是否包含元素
|
|
Node数据结构
|
|
树形化操作
|
|
遍历
假设key和value都是String型
- 根据
entrySet()通过Iterator遍历
|
|
根据
keySet()通过Iterator遍历12345Iterator iter = map.keySet().iterator();while(iter.hasNext()){key = (String)iter.next();value = (String)map.get(key);}根据
value()通过Iterator遍历1234Iterator iter = map.values().iterator();while(iter.hasNext()){value = (String)iter.next;}